Inference¶
Inference is an open-source computer vision deployment hub by Roboflow. It handles model serving, video stream management, pre/post-processing, and GPU/CPU optimization so you can focus on building your application.
Architecture¶
Read more about the Inference architecture here. Quick links:
inference_sdk · inference_cli · Inference server · inference
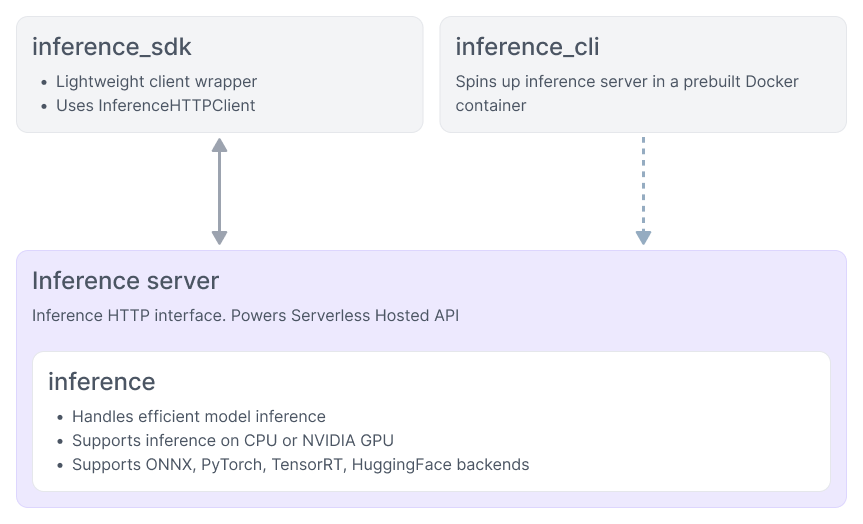
Features¶
- Model Serving - Object detection, classification, segmentation, keypoint detection, OCR, VQA, gaze detection, and more. Supports pre-trained, fine-tuned, and foundation models.
- Video Streaming - Efficient
InferencePipelinefor consuming camera feeds, RTSP streams, and video files with automatic frame management and state tracking. - Speed - Automatic parallelization, hardware acceleration, dynamic batching, and optional TensorRT quantization.
- Extensibility - Open source (Apache 2.0). Add custom models, Workflow blocks, and backends.
Deploy Anywhere¶
| Serverless | Dedicated | Self-Hosted | |
|---|---|---|---|
| Fine-Tuned & Pre-Trained Models | ✅ | ✅ | ✅ |
| Workflows | ✅ | ✅ | ✅ |
| Foundation Models | ✅ | ✅ | |
| Video Streaming | ✅ | ✅ | |
| Dynamic Python Blocks | ✅ | ✅ | |
| Runs Offline | ✅ | ||
| Billing | Per-Call | Hourly | Free + metered |
- Serverless - Pay-per-Inference, scales to zero. Doesn't support large foundation models.
- Dedicated - Single-tenant VMs with optional GPU. Supports larger foundation models (SAM 2, Florence-2, PaliGemma). Billed hourly.
- Self-Hosted - Run on your own hardware. Install guide →
- Bring Your Own Cloud - Self-host on AWS, Azure, or GCP for enterprise compliance.
Quick Start¶
Install the inference-sdk:
pip install inference-sdk
To self-host, start a local Inference server with the inference-cli:
pip install inference-cli && inference server start --port 9001
Then run inference:
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(
# api_url="https://serverless.roboflow.com", # for Roboflow hosted inference
api_url="http://localhost:9001", # for self-hosted inference
api_key="YOUR_API_KEY", # For private/fine-tuned models
)
image_url="https://media.roboflow.com/inference/people-walking.jpg"
results = client.infer(image_url, model_id="rfdetr-small")
For more information, see Run a model.
Related Products¶
Upload data, annotate images, train and deploy models. Get your API key.
Browse and use community datasets and models. Pass any Universe model_id directly to Inference.

Post-process results: decode predictions, plot bounding boxes, track objects, slice images for small object detection.
Open Source¶
Core functionality is open source under Apache 2.0. View on GitHub · Contribute
Models are subject to their underlying architecture licenses (details). Cloud-connected features require a Roboflow API key.