Inference pipeline
The Inference Pipeline interface is made for streaming and is likely the best route to go for real time use cases. It is an asynchronous interface that can consume many different video sources including local devices (like webcams), RTSP video streams, video files, etc. With this interface, you define the source of a video stream and sinks.
Quickstart¶
To use fine-tuned models with Inference, you will need a Roboflow API key. If you don't already have a Roboflow account, sign up for a free Roboflow account. Then, retrieve your API key from the Roboflow dashboard. Run the following command to set your API key in your coding environment:
export ROBOFLOW_API_KEY=<your api key>
Learn more about using Roboflow API keys in Inference
Then, install Inference:
We recommend using python virtual environment (venv) to isolate dependencies of inference.
To install Inference via pip:
pip install inference
If you have an NVIDIA GPU, you can accelerate your inference with:
pip install --extra-index-url https://download.pytorch.org/whl/cu124 inference-gpu
# please adjust the --extra-index-url to CUDA version installed in your OS
# https://download.pytorch.org/whl/cu<major><minor>, for instance https://download.pytorch.org/whl/cu130 for CUDA 13.0
# alternativelly use
uv pip install inference-gpu
Next, create an Inference Pipeline:
# import the InferencePipeline interface
from inference import InferencePipeline
# import a built-in sink called render_boxes (sinks are the logic that happens after inference)
from inference.core.interfaces.stream.sinks import render_boxes
api_key = "YOUR_ROBOFLOW_API_KEY"
# Create an inference pipeline object
pipeline = InferencePipeline.init(
# set the model id to an rfdetr model (pre-trained on COCO)
model_id="rfdetr-large",
# set the video reference (source of video), it can be a link/path to a video file, an RTSP stream url,
# or an integer representing a device id (usually 0 for built in webcams)
video_reference="https://storage.googleapis.com/com-roboflow-marketing/inference/people-walking.mp4",
# tell the pipeline what to do with inference results. render_boxes is a built-in sink that renders boxes on top of the video
on_prediction=render_boxes,
# provide your roboflow api key for loading models from the roboflow api
api_key=api_key,
)
# Start the pipeline and join the thread that processes the video stream.
pipeline.start()
pipeline.join()
What is video reference?¶
Inference Pipelines can consume many different types of video streams.
- Device Id (integer): Providing an integer instructs a pipeline to stream video from a local device, like a webcam. Typically, built in webcams show up as device
0. - Video File (string): Providing the path to a video file will result in the pipeline reading every frame from the file, running inference with the specified model, then running the
on_predictionmethod with each set of resulting predictions. - Video URL (string): Providing the path to a video URL is equivalent to providing a video file path and voids needing to first download the video.
- RTSP URL (string): Providing an RTSP URL will result in the pipeline streaming frames from an RTSP stream as fast as possible, then running the
on_predictioncallback on the latest available frame. - List of elements that may be any of values described above.
How the InferencePipeline works?¶
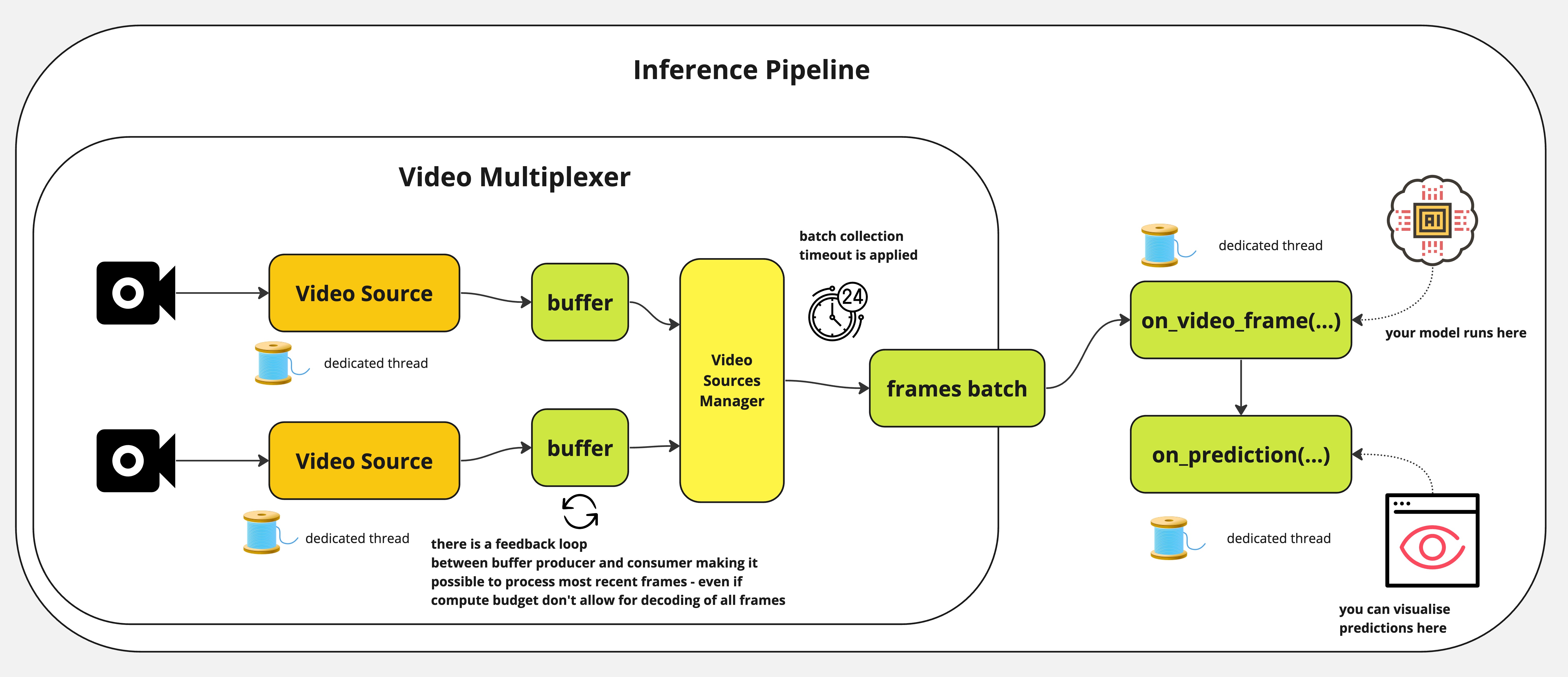
InferencePipeline spins a video source consumer thread for each provided video reference. Frames from videos are
grabbed by video multiplexer that awaits batch_collection_timeout (if source will not provide frame, smaller batch
will be passed to on_video_frame(...), but missing frames and predictions will be filled with None before passing
to on_prediction(...)). on_prediction(...) may work in SEQUENTIAL mode (only one element at once), or BATCH
mode - all batch elements at a time and that can be controlled by sink_mode parameter.
For static video files, InferencePipeline processes all frames by default, for streams - it is possible to drop
frames from the buffers - in favour of always processing the most recent data (when model inference is slow, more
frames can be accumulated in buffer - stream processing drop older frames and only processes the most recent one).
To enhance stability, in case of streams processing - video sources will be automatically re-connected once connectivity is lost during processing. That is meant to prevent failures in production environment when the pipeline can run long hours and need to gracefully handle sources downtimes.
How to provide a custom inference logic to InferencePipeline¶
InferencePipeline supports running custom inference logic. This means that instead of passing
a model ID, you can pass a custom callable. This callable should accept and VideoFrame return a dictionary with
results from the processing (as on_video_frame handler). It can be model predictions or results of any other processing you wish to execute.
It is important to note that the sink being used (on_prediction handler you use) - must be adjusted to the
specific format of on_video_frame(...) response. This way, you can shape video processing in a way you want.
# This is example, reference implementation - you need to adjust the code to your purposes
import os
import json
from inference.core.interfaces.camera.entities import VideoFrame
from inference import InferencePipeline
from typing import Any, List
TARGET_DIR = "./my_predictions"
class MyModel:
def __init__(self, weights_path: str):
self._model = your_model_loader(weights_path)
# before v0.9.18
def infer(self, video_frame: VideoFrame) -> Any:
return self._model(video_frame.image)
# after v0.9.18
def infer(self, video_frames: List[VideoFrame]) -> List[Any]:
# result must be returned as list of elements representing model prediction for single frame
# with order unchanged.
return self._model([v.image for v in video_frames])
def save_prediction(prediction: dict, video_frame: VideoFrame) -> None:
with open(os.path.join(TARGET_DIR, f"{video_frame.frame_id}.json")) as f:
json.dump(prediction, f)
my_model = MyModel("./my_model.pt")
pipeline = InferencePipeline.init_with_custom_logic(
video_reference="./my_video.mp4",
on_video_frame=my_model.infer,
on_prediction=save_prediction,
)
# start the pipeline
pipeline.start()
# wait for the pipeline to finish
pipeline.join()
InferencePipeline with Roboflow Workflows¶
InferencePipeline can also run Roboflow Workflows, as shown below:
from inference import InferencePipeline
from inference.core.interfaces.camera.entities import VideoFrame
from inference.core.interfaces.stream.sinks import render_boxes
def workflows_sink(
predictions: dict,
video_frame: VideoFrame,
) -> None:
render_boxes(
predictions["predictions"][0],
video_frame,
display_statistics=True,
)
# here you may find very basic definition of workflow - with a single object detection model.
# Please visit workflows docs: https://github.com/roboflow/inference/tree/main/inference/enterprise/workflows to
# find more examples.
workflow_specification = {
"specification": {
"version": "1.0",
"inputs": [
{"type": "InferenceImage", "name": "image"},
],
"steps": [
{
"type": "ObjectDetectionModel",
"name": "step_1",
"image": "$inputs.image",
"model_id": "rfdetr-small",
"confidence": 0.5,
}
],
"outputs": [
{"type": "JsonField", "name": "predictions", "selector": "$steps.step_1.*"},
],
}
}
pipeline = InferencePipeline.init_with_workflow(
video_reference="./my_video.mp4",
workflow_specification=workflow_specification,
on_prediction=workflows_sink,
image_input_name="image", # adjust according to name of WorkflowImage input you define
video_metadata_input_name="video_metadata" # AVAILABLE from v0.17.0! adjust according to name of WorkflowVideoMetadata input you define
)
# start the pipeline
pipeline.start()
# wait for the pipeline to finish
pipeline.join()
You can initialise InferencePipeline with workflow registered in Roboflow App - providing your workspace_name and workflow_id:
pipeline = InferencePipeline.init_with_workflow(
video_reference="./my_video.mp4",
workspace_name="<your_workspace>",
workflow_id="<your_workflow_id_to_be_found_in_workflow_url>",
on_prediction=workflows_sink,
)
Workflows profiling
You can profile your Workflow execution inside InferencePipeline when
you export environmental variable ENABLE_WORKFLOWS_PROFILING=True. Additionally, you can tune the
number of frames you keep in profiler buffer via another environmental variable WORKFLOWS_PROFILER_BUFFER_SIZE.
init_with_workflow(...) was also given a new parameter profiling_directory which can be adjusted to
dictate where to save the trace.
Sinks¶
Sinks define what an Inference Pipeline should do with each prediction. A sink is a function with the following signature:
from typing import Union, List, Optional
from inference.core.interfaces.camera.entities import VideoFrame
def on_prediction(
predictions: Union[dict, List[Optional[dict]]],
video_frame: Union[VideoFrame, List[Optional[VideoFrame]]],
) -> None:
for prediction, frame in zip(predictions, video_frame):
if prediction is None:
# EMPTY FRAME
continue
# SOME PROCESSING
The arguments are:
predictions: A dictionary (or list of dicts when using multiple video sources) that is the response object resulting from a call to a model'sinfer(...)method.video_frame: A VideoFrame object (or list of VideoFrames) containing metadata and pixel data from the video frame.
See more info in Custom Sink section on how to create sink.
Usage¶
You can also make on_prediction accepting other parameters that configure its behaviour, but those needs to be
latched in function closure before injection into InferencePipeline init methods.
from functools import partial
from inference.core.interfaces.camera.entities import VideoFrame
from inference import InferencePipeline
def on_prediction(
predictions: dict,
video_frame: VideoFrame,
my_parameter: int,
) -> None:
# you need to implement your logic here, with `my_parameter` used
pass
pipeline = InferencePipeline.init(
video_reference="./my_video.mp4",
model_id="rfdetr-small",
on_prediction=partial(on_prediction, my_parameter=42),
)
Custom Sink Tutorial¶
Let's walk through building a custom sink step by step. First, a simple sink that prints the frame ID:
from inference import InferencePipeline
# import VideoFrame for type hinting
from inference.core.interfaces.camera.entities import VideoFrame
# define sink function
def my_custom_sink(predictions: dict, video_frame: VideoFrame):
# print the frame ID of the video_frame object
print(f"Frame ID: {video_frame.frame_id}")
pipeline = InferencePipeline.init(
model_id="rfdetr-large",
video_reference="https://storage.googleapis.com/com-roboflow-marketing/inference/people-walking.mp4",
on_prediction=my_custom_sink,
)
pipeline.start()
pipeline.join()
The output should look something like:
Frame ID: 1
Frame ID: 2
Frame ID: 3
Now let's do something more useful and use our custom sink to visualize predictions with Supervision:
from inference import InferencePipeline
from inference.core.interfaces.camera.entities import VideoFrame
# import opencv to display our annotated images
import cv2
# import supervision to help visualize our predictions
import supervision as sv
# create a bounding box annotator and label annotator to use in our custom sink
label_annotator = sv.LabelAnnotator()
box_annotator = sv.BoxAnnotator()
def my_custom_sink(predictions: dict, video_frame: VideoFrame):
# get the text labels for each prediction
labels = [p["class"] for p in predictions["predictions"]]
# load our predictions into the Supervision Detections api
detections = sv.Detections.from_inference(predictions)
# annotate the frame using our supervision annotator, the video_frame, the predictions (as supervision Detections), and the prediction labels
image = label_annotator.annotate(
scene=video_frame.image.copy(), detections=detections, labels=labels
)
image = box_annotator.annotate(image, detections=detections)
# display the annotated image
cv2.imshow("Predictions", image)
cv2.waitKey(1)
pipeline = InferencePipeline.init(
model_id="rfdetr-large",
video_reference="https://storage.googleapis.com/com-roboflow-marketing/inference/people-walking.mp4",
on_prediction=my_custom_sink,
)
pipeline.start()
pipeline.join()
You should see something like this on your screen:
Custom Sinks (Advanced)¶
To create a custom sink, define a new function with the appropriate signature.
from typing import Union, List, Optional, Any
from inference.core.interfaces.camera.entities import VideoFrame
def on_prediction(
predictions: Union[Any, List[Optional[dict]]],
video_frame: Union[VideoFrame, List[Optional[VideoFrame]]],
) -> None:
if not issubclass(type(predictions), list):
# this is required to support both sequential and batch processing with single code
# if you use only one mode - you may create function that handles with only one type
# of input
predictions = [predictions]
video_frame = [video_frame]
for prediction, frame in zip(predictions, video_frame):
if prediction is None:
# EMPTY FRAME
continue
# SOME PROCESSING
InferencePipeline provides a sink_mode parameter to control how predictions are passed to your sink.
With SinkMode.SEQUENTIAL - each frame and prediction triggers a separate call to the sink. With SinkMode.BATCH -
a list of frames and predictions is provided to the sink, always aligned in the order of video sources - with None
values in the place of video frames / predictions that were skipped due to batch_collection_timeout.
SinkMode.ADAPTIVE is the default mode - for a single video input, the pipeline behaves as if running in
SinkMode.SEQUENTIAL. To handle multiple videos, the sink needs to accept
predictions: List[Optional[dict]] and video_frame: List[Optional[VideoFrame]]. It is also
possible to process multiple videos using simpler sinks - but then SinkMode.SEQUENTIAL should be used, causing
the sink to be called on each prediction element separately.
Why there is Optional in List[Optional[dict]] and List[Optional[VideoFrame]]?¶
It may happen that it is not possible to collect video frames from all the video sources (for instance when one of the
source disconnected and re-connection is attempted). predictions and video_frame are ordered matching the order of
video_reference list of InferencePipeline and None elements will appear in position of missing frames. We
provide this information to sink, as some sinks may require all predictions and video frames from the batch to
be provided (even if missing) - for example: render_boxes(...) sink needs that information to maintain the position
of frames in tiles mosaic.
prediction
Predictions are provided to the sink as a dictionary containing keys:
predictions: predictions - either for single frame or batch of frames. Content depends on which model runs behindInferencePipeline- for Roboflow models - it will come as dict or list of dicts. The schema of elements is given below.
Depending on the model output, predictions look differently. You must adjust sink to the prediction format. For instance, Roboflow object-detection prediction contains the following keys:
x: The center x coordinate of the predicted bounding box in pixelsy: The center y coordinate of the predicted bounding box in pixelswidth: The width of the predicted bounding box in pixelsheight: The height of the predicted bounding box in pixelsconfidence: The confidence value of the prediction (between 0 and 1)class: The predicted class nameclass_id: The predicted class ID
Built-in Sinks¶
Inference has several sinks built in that are ready to use.
render_boxes(...)¶
The render boxes sink visualizes predictions and overlays them on a stream. It uses Supervision annotators to render the predictions and display the annotated frame.
It only works for Roboflow models that yield detection-based output (object-detection, instance-segmentation, keypoint-detection), yet not all details of predictions may be
displayed by default (like detected key-points).
UDPSink(...)¶
The UDP sink broadcasts predictions over a UDP port. This port can be listened to by client code for further processing. It uses Python-default json serialisation - so predictions must be serializable, otherwise an error will be thrown.
multi_sink(...)¶
The Multi-Sink combines multiple sinks so that multiple actions can happen on a single inference result.
VideoFileSink(...)¶
The Video File Sink visualizes predictions, similar to the render_boxes(...) sink, however, instead of displaying the annotated frames, it saves them to a video file.
All constraints related to render_boxes(...) apply.
Model Weights Download¶
Model weights are downloaded automatically the first time you run inference. You can pre-download weights by initializing the pipeline once while connected to the internet:
from inference import InferencePipeline
pipeline = InferencePipeline.init(
model_id="rfdetr-base",
video_reference=0,
on_prediction=lambda predictions, video_frame: None,
api_key="YOUR_ROBOFLOW_API_KEY",
)
pipeline.start()
pipeline.terminate()
print("Model weights downloaded successfully!")
Alternatively, use get_model() to pre-download weights:
from inference import get_model
get_model("rfdetr-base")
You can verify cached models by checking the cache directory:
ls -lh /tmp/cache
You should see directories for each cached model, typically named with the model ID.
Tip
Read more about weights caching, persistent storage, and Docker configuration.
Other Pipeline Configuration¶
Inference Pipelines are highly configurable. Configurations include:
max_fps: Used to set the maximum rate of frame processing.confidence: Confidence threshold used for inference.iou_threshold: IoU threshold used for inference.video_source_properties: Optional dictionary of properties to configure the video source, corresponding to cv2 VideoCapture properties cv2.CAP_PROP_*. See the OpenCV Documentation for a list of all possible properties.
from inference import InferencePipeline
pipeline = InferencePipeline.init(
...,
max_fps=10,
confidence=0.75,
iou_threshold=0.4,
video_source_properties={
"frame_width": 1920.0,
"frame_height": 1080.0,
"fps": 30.0,
},
)
See the reference docs for the full list of Inference Pipeline parameters.