The pillars of Workflows¶
In the Roboflow Workflows ecosystem, various components work together seamlessly to power your applications. Some of these elements will be part of your daily interactions, while others operate behind the scenes to ensure smooth and efficient application performance. The core pillars of the ecosystem include:
-
Workflows UI: The intuitive interface where you design and manage your workflows.
-
Workflow Definition: An interchangeable format that serves as a program written in the "workflows" language, defining how your workflows operate.
-
Workflows Blocks: Modular components that perform specific tasks within your workflows, organized in plugins which can be easily created and injected into the ecosystem.
-
Workflows Compiler and Execution Engine: The systems that compile your workflow definitions and execute them, ensuring everything runs smoothly in your environment of choice.
We will explore each of these components, providing you with a foundational understanding to help you navigate and utilize the full potential of Roboflow Workflows effectively.
Workflows UI¶
Traditionally, building machine learning applications involves complex coding and deep technical expertise. Roboflow Workflows simplifies this process in two key ways: providing pre-built blocks (which will be described later), and delivering user-friendly GUI.
The interface allows you to design applications without needing to write code. You can easily connect components together and achieve your goals without a deep understanding of Python or the underlying workflow language.
Thanks to the UI, creating powerful machine learning solutions is straightforward and accessible, allowing you to focus on innovation rather than intricate programming.
While not essential, the UI is a highly valuable component of the Roboflow Workflows ecosystem. At the end of the workflow creation process, it generates the workflow definition required for the Compiler and Execution Engine to run the workflow.
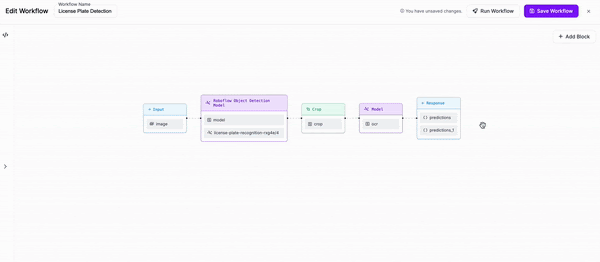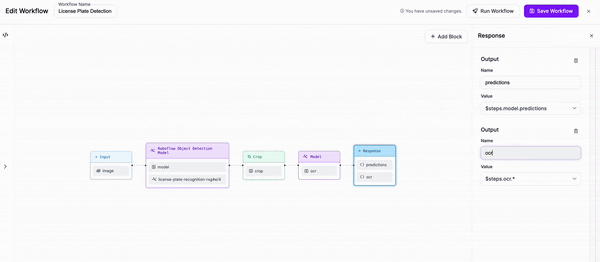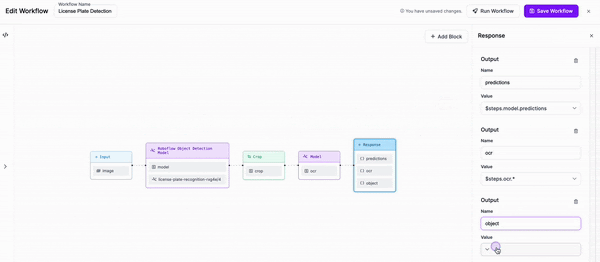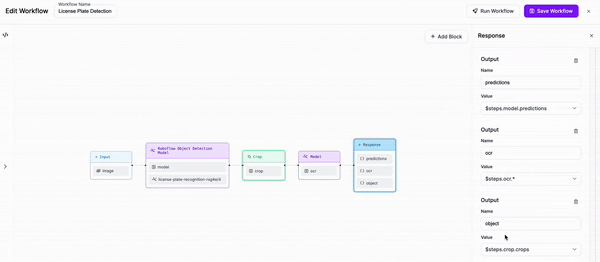
Workflow definition¶
A workflow definition is essentially a document written in the internal programming language of Roboflow Workflows. It allows you to separate the design of your workflow from its execution. You can create a workflow definition once and run it in various environments using the Workflows Compiler and Execution Engine.
You have two options for creating a workflow definition: use the UI to design it visually, or write it from scratch if you’re comfortable with the Workflows language. More details on writing definitions manually are available here. For now, it's important to grasp the role of the definition within the ecosystem.
A workflow definition is, in fact, a JSON document that outlines:
-
Inputs: These are either images or configuration parameters that influence how the workflow operates. Instead of hardcoding values, inputs are placeholders that will be replaced with actual data during execution.
-
Steps: These are instances of workflow blocks. Each step takes inputs from either the workflow inputs or the outputs of previous steps. The sequence and connections between steps determine the execution order.
-
Outputs: Specify the field names in the execution result and reference step outputs. During runtime, the referenced values are dynamically provided based on the results of workflow execution.
Workflow blocks¶
For users of Roboflow Workflows, blocks are essentially black boxes engineered to perform specific operations. They act as templates for the steps executed within a workflow, each defining its own set of inputs, configuration properties, and outputs.
When adding a block to your workflow, you need to provide its inputs by referencing either the workflow’s input or the output of another step. You also specify the values for any required parameters. Once the step is incorporated, its outputs can be referenced by subsequent steps, allowing for seamless integration and chaining of operations.
The creation of blocks is a more advanced topic, which you can explore here. It’s essential to understand that blocks are grouped in workflow plugins, which are standard Python libraries. Roboflow offers its own set of plugins, and community members are encouraged to create their own. The process of importing a plugin into your environment is detailed here.
Feel free to explore Workflow blocks prepared by Roboflow.
Workflows Compiler and Execution Engine¶
The Compiler and Execution Engine are essential components of the Roboflow Workflows ecosystem, doing the heavy lifting so you don't have to.
Much like a traditional programming compiler or interpreter, these components translate your workflow definition — a program you create using reusable blocks — into a format that can be executed by a computer. The workflow definition acts as a blueprint, with blocks functioning like functions in programming, connected to produce the desired outcomes.
Roboflow provides these tools as part of their Inference Server (which can be deployed locally or accessed via the Roboflow Hosted platform), video processing component, and Python package, making it easy to run your workflows in various environments.
For a deeper dive into the Compiler and Execution Engine, please refer to our detailed documentation.